什麼是 robots.txt?
robots.txt 是一個放在網站根目錄中的簡單文本檔案,用於指導網路爬蟲(如 Googlebot)哪些頁面應該抓取,哪些頁面應被忽略。當爬蟲拜訪一個網站時,它會先讀取該網站的 robots.txt,然後根據檔案內的規則行動。
為什麼要使用 robots.txt?
1. 控制爬蟲行為:可以告訴爬蟲不要索引特定的頁面或資料夾,例如不必要的管理後台或測試頁面。這有助於節省伺服器資源,也能避免讓不相關或敏感的內容出現在搜索引擎結果中。
2. 優化網站效能:如果一個網站有大量的頁面,並且不希望爬蟲花費資源在無用的內容上,robots.txt 可以有效優化網頁索引的效率。
以下是一個常見的 robots.txt 範例:
User-agent: *
Disallow: /admin/
Disallow: /private/
User-agent: *:適用於所有的網路爬蟲。
Disallow: /admin/:阻止爬蟲抓取網站上的 /admin/ 資料夾。
這樣可以防止這些資料夾中的頁面出現在搜索結果中,但這些頁面仍然可以被人手動輸入 URL 訪問。因此如果試圖「隱藏」敏感資料,這可能反而會暴露出敏感的路徑。因此如果該頁面具有敏感資料,應採取更嚴格的措施,例如身份驗證或伺服器端的存取控制。
那進入今天的第一題~
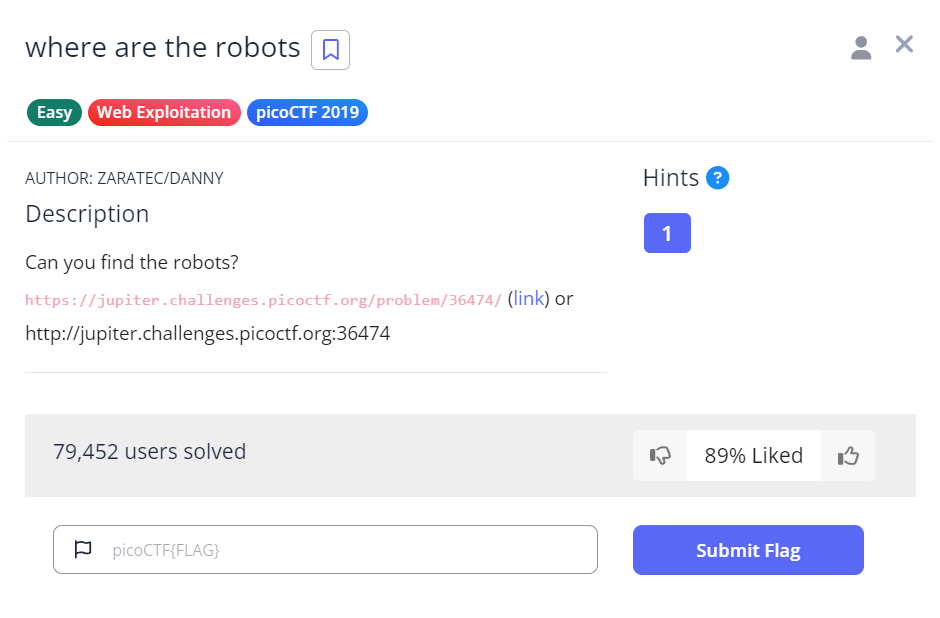
看到這裡,還記得剛剛上片提到的 robots.txt 嗎?這就來現學現賣
在 URL 後面接著輸入robots.txt,頁面告訴我們有一個/477ce.html頁面被隱藏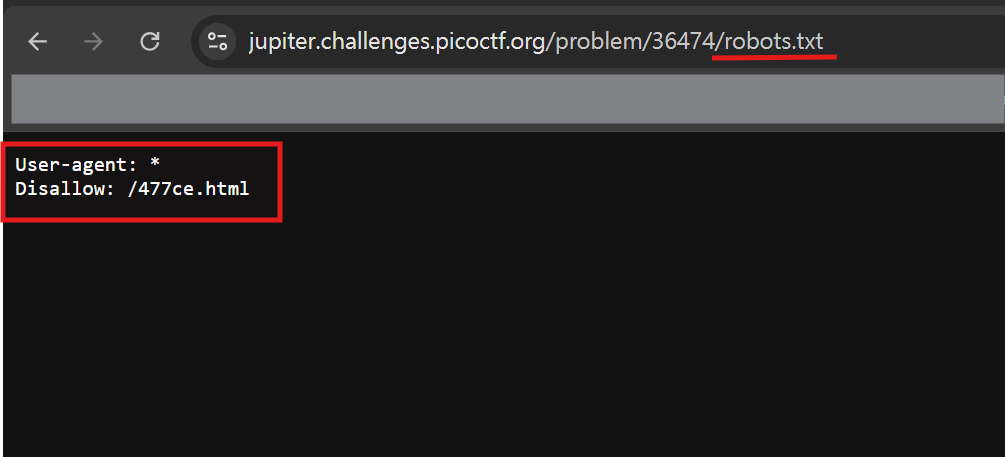
將 URL 後接上/477ce.html,flag 出現在我們眼前惹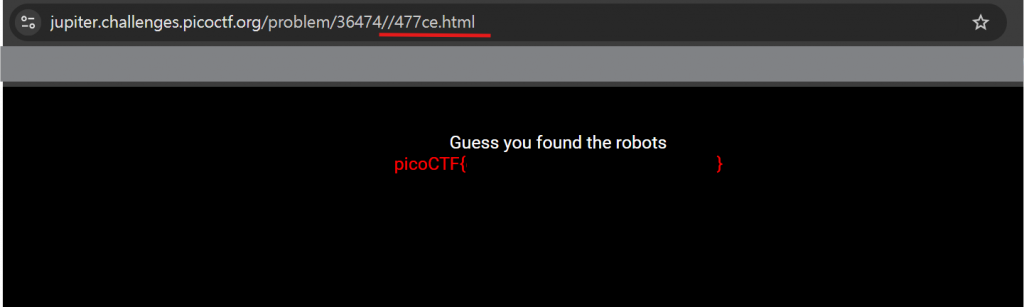
接著進到第二題 (´∀ ˋ)
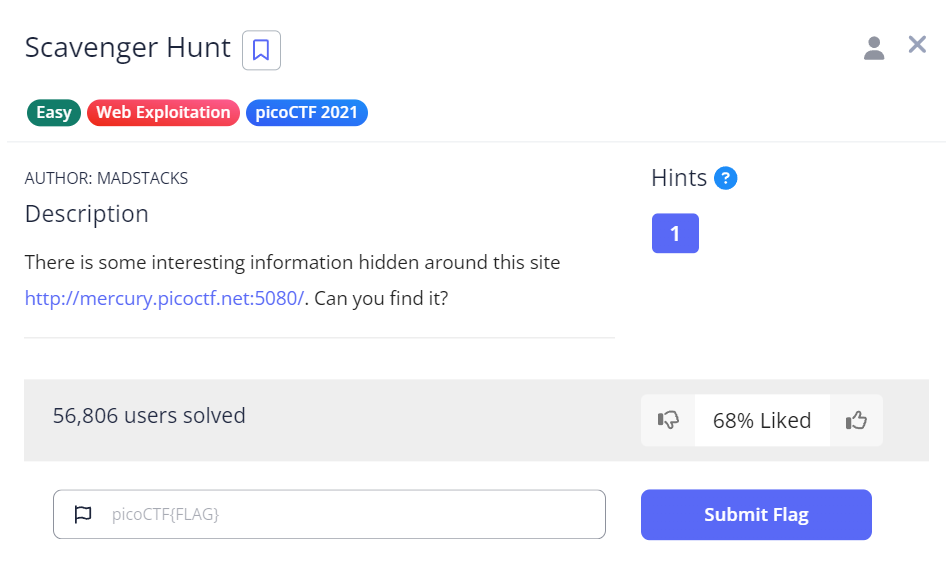
按下F12後觀察 Elements 中 html 的程式碼,尾端發現註解沒有被清乾淨,找到 1/5 part 的 flag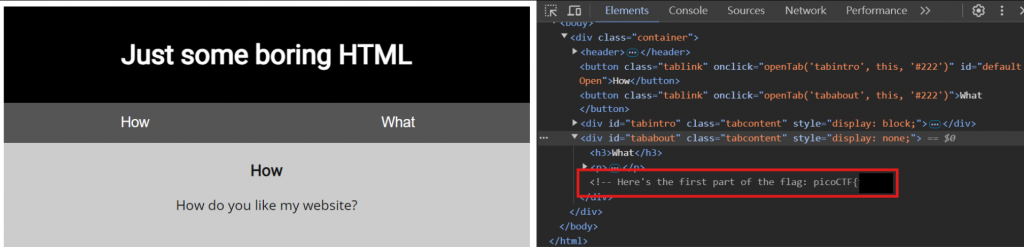
到 Application 把 CSS 跟 JavaScript 的程式碼也一併檢查,在mycss.css發現 2/5 part flag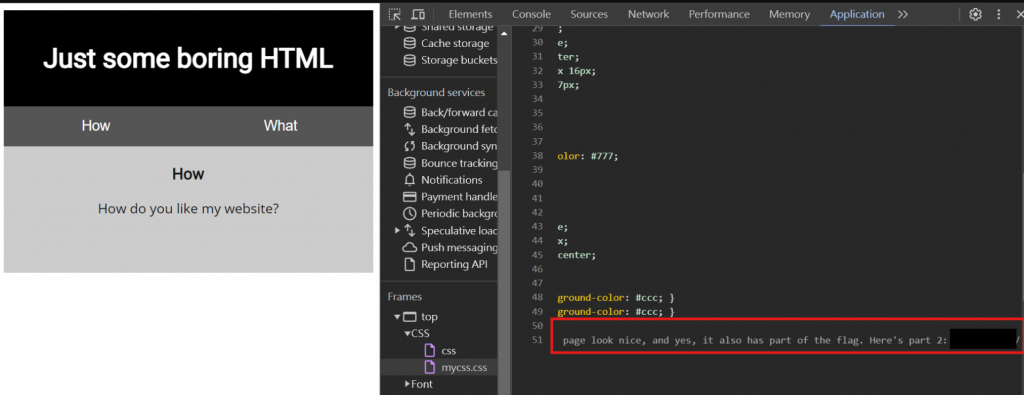
在myjs.js這頁程式中,我們獲得了提示,似乎在提示我們可以查看 robotx.txt 頁面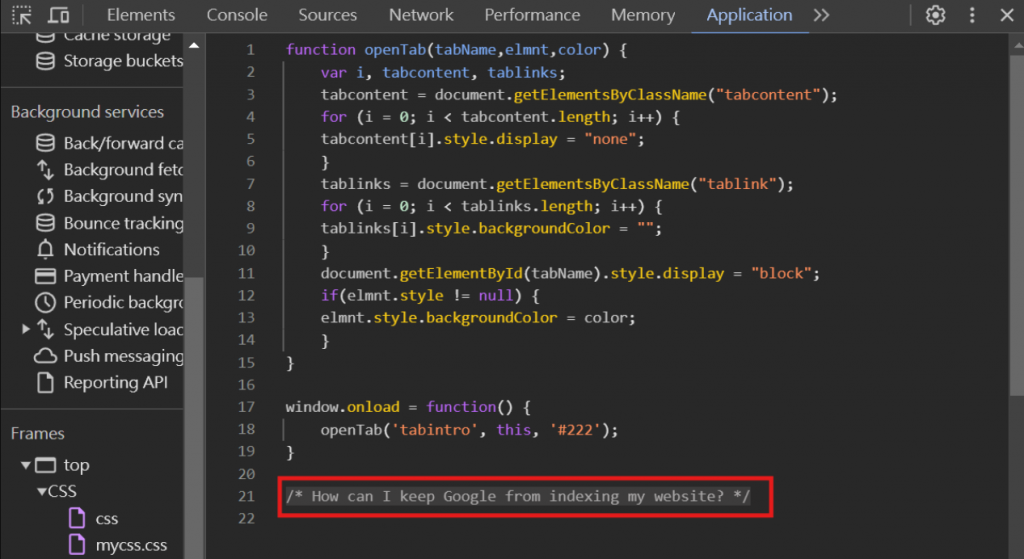
我們在 robots.txt 拿到 3/5 part flag,並且拿到# I think this is an apache server... can you Access the next flag?這個提示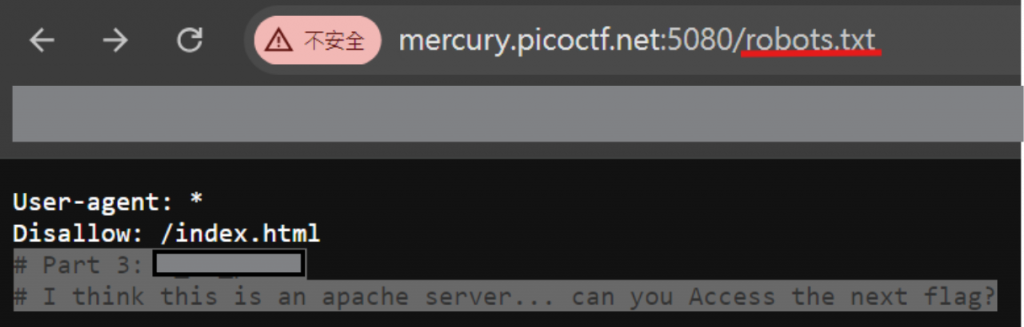
htaccess 為 Apache server 下對於系統目錄進行各種權限規則設置的文件,於是把 URL 後面加上.htaccess,拿到 4/5 part flag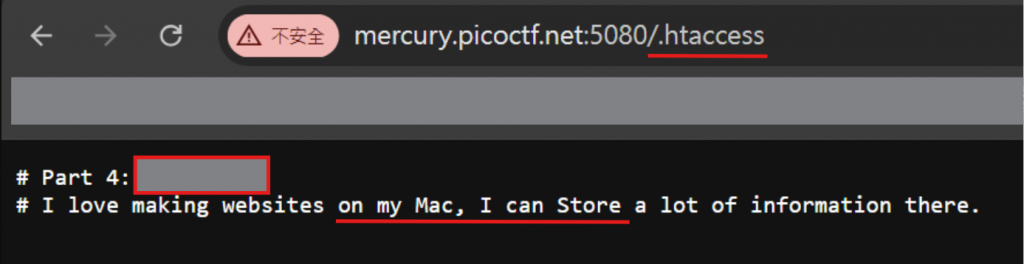
I love making websites on my Mac, I can Store a lot of information there. 這邊可以往 Mac 跟 Store 的方向去發想,而.DS_Store是 Mac OS X 作業系統的隱藏文件格式。於是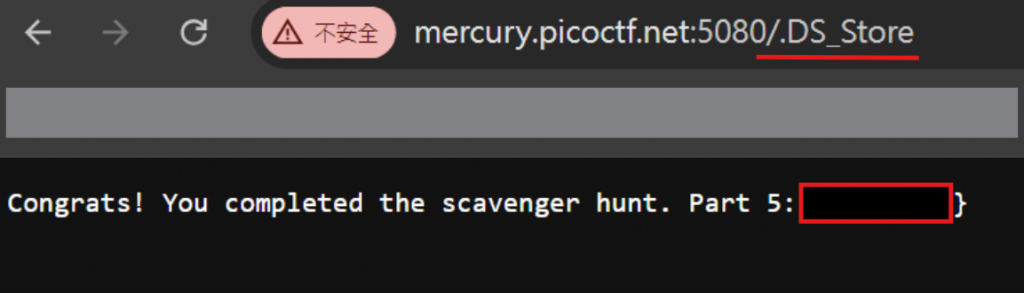
將 1~5 part 的 flag 合併在一起後,就是完整的 flag 啦!
今天的練習就到這邊,以下是參考資料,請搭配服用:
cloudflare robots.txt
robots.txt 範例教學
內文如有錯誤,還請不吝指教~

